Managing Multiple Research Sources Effectively Without Losing Context
The Research Source Fragmentation Problem
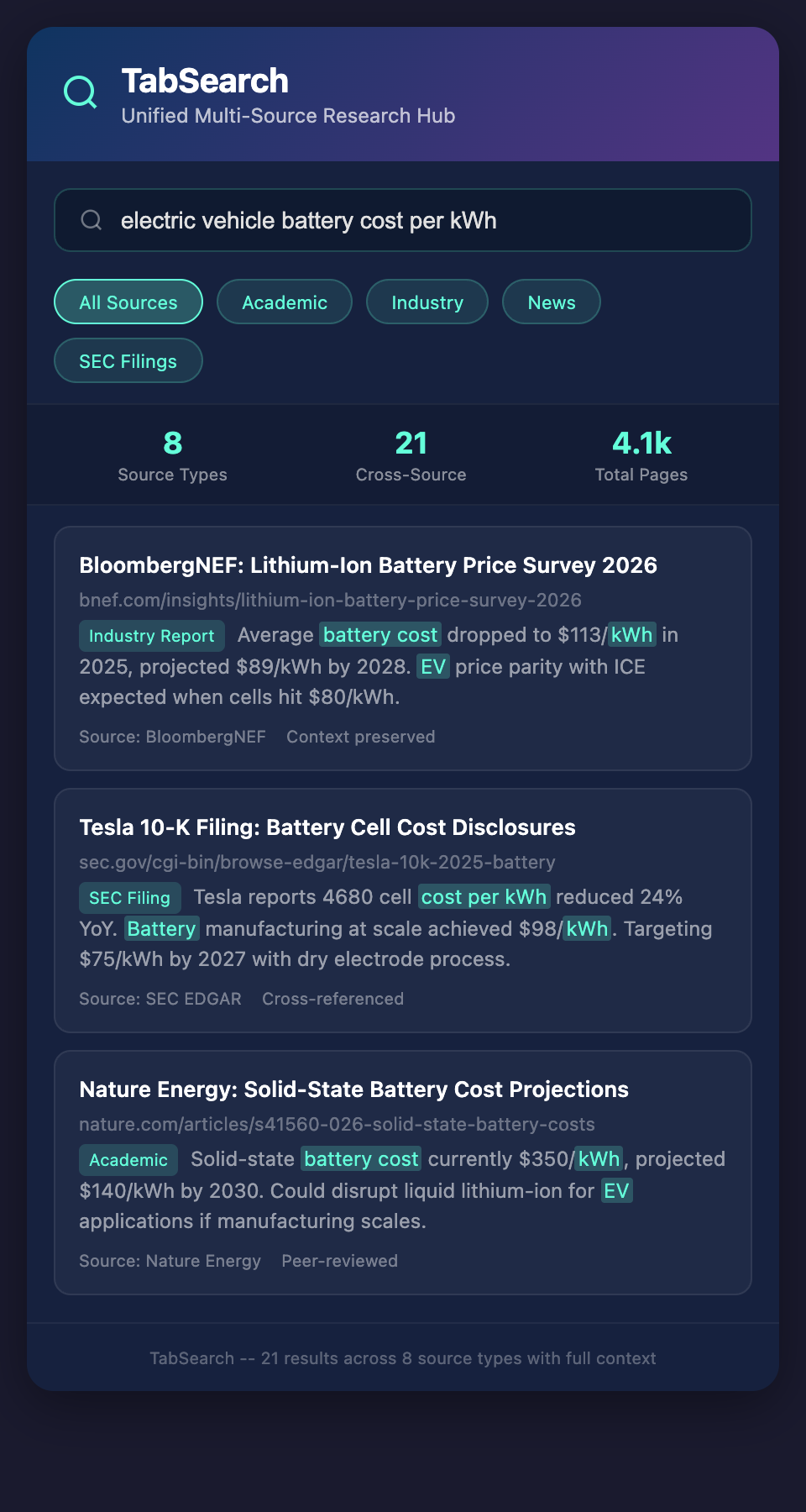
Consider the morning of a typical competitive intelligence analyst:
7:45 AM: Email notification from a competitor tracking service mentions a new job posting
8:15 AM: Slack message from a colleague links to an article about market consolidation
8:30 AM: News alert about a competitor press release arrives in Gmail
9:00 AM: A customer mention of a competitive capability appears in a CRM note
9:15 AM: A report subscriber sends an industry analysis to Dropbox
9:45 AM: LinkedIn algorithm serves a profile update for a competitor's new executive
Before mid-morning, you've collected intelligence from six sources in different formats, across different platforms, with varying levels of detail and reliability. By Friday, you've touched 50+ sources. By month-end, it's in the hundreds.
The core problem isn't collecting sources—it's that each source lives in a different system, with different search capabilities, different retention policies, and different degrees of integration with your analysis workflow.
Why Source Context Matters
Context transforms raw information into intelligence:
Source credibility: A claim in a competitor's earnings call carries different weight than a rumor on Reddit
Timing: Understanding when you first learned something informs competitive analysis. "We knew about this pivot three months before they announced it" is strategically different from "We learned about this at the same time the market did"
Corroboration: One customer mentioning a competitive feature is anecdotal. Five customers mentioning it is evidence of a genuine threat
Evolution: Tracking how a competitor's messaging about a feature evolved over six months tells you whether it's strategic or experimental
Most knowledge workers capture sources but lose context. A saved article without the date you found it, a customer quote without which customer or when, a competitor announcement without the broader business context that makes it significant.
A System for Managing Multiple Sources
Centralized Source Intake
Every source should flow through a single intake process, regardless of where it originates:
From email: A forwarding rule or integration sends article recommendations into your centralized system
From Slack: An integration captures links shared in designated research channels with conversation context
From news alerts: RSS feeds, email digests, and alert services all feed into one place
From manual capture: You can directly add sources via browser extension or manual entry
From tools and databases: Integrations with market research platforms, financial databases, and industry-specific tools
Without centralized intake, you're managing multiple workflows. With it, everything enters through one funnel and exits through one search interface.
Structured Source Metadata
Not all intelligence sources are created equal. Capture these details for every source:
Primary dimensions:
-
Source type (news article, research report, earnings call transcript, customer conversation, social media, job posting, patent filing)
-
Subject (specific competitor, market trend, technology development, regulatory change)
-
Geographic scope (global, North America, specific country)
-
Time relevance (breaking/current, early indicator, historical context)
Reliability markers:
-
Source credibility tier (official statements like earnings calls rank higher than social media rumors)
-
Corroboration level (number of independent sources confirming the same information)
-
Confidence in accuracy (how certain are you this information is correct)
Workflow markers:
-
Analyzed: Has this source been incorporated into formal analysis?
-
Actionable items identified: Does this source suggest specific company actions?
-
Follow-up required: What related intelligence should we seek to validate or understand this source?
This structured metadata means you can filter for only corroborated information, only recent sources, only from credible outlets—without manually reviewing each item.
Context-Preserving Search
When you search your sources, you should see not just the matching source but the surrounding context:
Temporal context: When you find an article, immediately see other sources added around the same date. Did your competitors announce related things in the same period?
Thematic context: When you search "artificial intelligence," see related sources about automation, machine learning, specific AI tools competitors are using
Evidentiary context: When you find a claim, see what other sources support or contradict it
Relationship mapping: When you find information about a specific competitor, see connections to their customers, partners, funding sources, and executives
Most search systems return isolated results. The best search systems return results with context.
Categorizing for Multiple Retrieval Paths
Since different people search differently, ensure sources are categorized for multiple discovery paths:
By competitor: Sales reps searching "What's Competitor A doing?" should find everything about that company
By capability/feature: Product teams searching "payment processing" should find all sources mentioning payment-related capabilities
By geographic market: Expansion teams searching "APAC market dynamics" should find relevant market intelligence
By time period: Strategic planning teams searching "What changed in the last 90 days?" should get quarterly snapshots
By business question: Someone asking "Are we at risk of market disruption?" should find all relevant macro-level trends
Implement this by allowing sources to have multiple tags, and by providing faceted search that lets users navigate by any dimension.
Practical Implementation
Phase 1: Map current sources (Week 1)
Create an inventory: "Where is my competitive intelligence currently captured?" List emails, Slack channels, shared drives, bookmarks, spreadsheets, and other sources. You'll likely find 8-15 different systems.
Phase 2: Establish intake process (Week 2)
Decide on your single source of truth for all captured intelligence. This becomes your "inbox" for new sources. Set up integrations or manual processes to flow sources into this system.
Phase 3: Implement structured capture (Week 3)
Train the team on what metadata to capture with each source. Start with the five fields that matter most for your use case, then expand.
Phase 4: Build retrieval systems (Week 4)
Implement full-text search and faceted navigation so users can find sources by competitor, by topic, by time period, and by keyword combinations.
The Sustainability Challenge
A source database decays without maintenance:
-
Outdated information crowds out current intelligence
-
Tags become inconsistent as different team members add sources
-
Duplicates accumulate when the same story is shared via multiple channels
-
Dead links break as articles disappear
Allocate time weekly for:
-
Intake review: New sources added this week are reviewed for quality and proper tagging
-
Tag maintenance: Inconsistent or deprecated tags are cleaned up
-
Duplicate removal: The same information added through multiple channels is consolidated
-
Link checking: Broken links are removed or archived copies are used
This maintenance feels like overhead but prevents your knowledge base from becoming a graveyard of useful information you can no longer access.
The Competitive Intelligence Timeline
When sources are properly managed, you can construct detailed timelines:
"Competitor A's pivot to the mid-market happened in this order: (1) They hired a mid-market VP in July [source], (2) Their messaging shifted in August [source], (3) They announced partnerships with integration partners targeting SMBs in September [source], (4) Their pricing changed in October to support lower ACV [source]."
This timeline tells a strategic story. Single sources are hints; managed sources are evidence.
The companies winning competitive battles aren't the ones with the best sources—they're the ones who've built systematic processes to capture, contextualize, and retrieve sources efficiently. Start building that system this week.
Stop losing competitive intelligence to fragmented, context-poor data silos. Join our waitlist to see how to centralize, contextualize, and search all your research sources from one place.